
Hi! I am a third year EECS PhD student at UC Berkeley working with Sergey Levine. I previously did my undergraduate degree at the University of Toronto in Engineering Science (Robotics) advised by Tim Barfoot. My research focuses on generalist robot navigation and interfacing with robots through natural language. I am also interested in mobile manipulation and pushing the boundaries of leveraging foundation models and non-robot data to improve robot learning.
Hi! I am a third year PhD student at UC Berkeley working with Sergey Levine. I previously did my undergraduate degree at the University of Toronto in Engineering Science (Robotics) advised by Tim Barfoot. My research focuses on generalist robot navigation and interfacing with robots through natural language. I am also interested in mobile manipulation and pushing the boundaries of leveraging foundation models and non-robot data to improve robot learning.
Publications
Here is a list of my publications to date. Please feel free to reach out with questions!
-
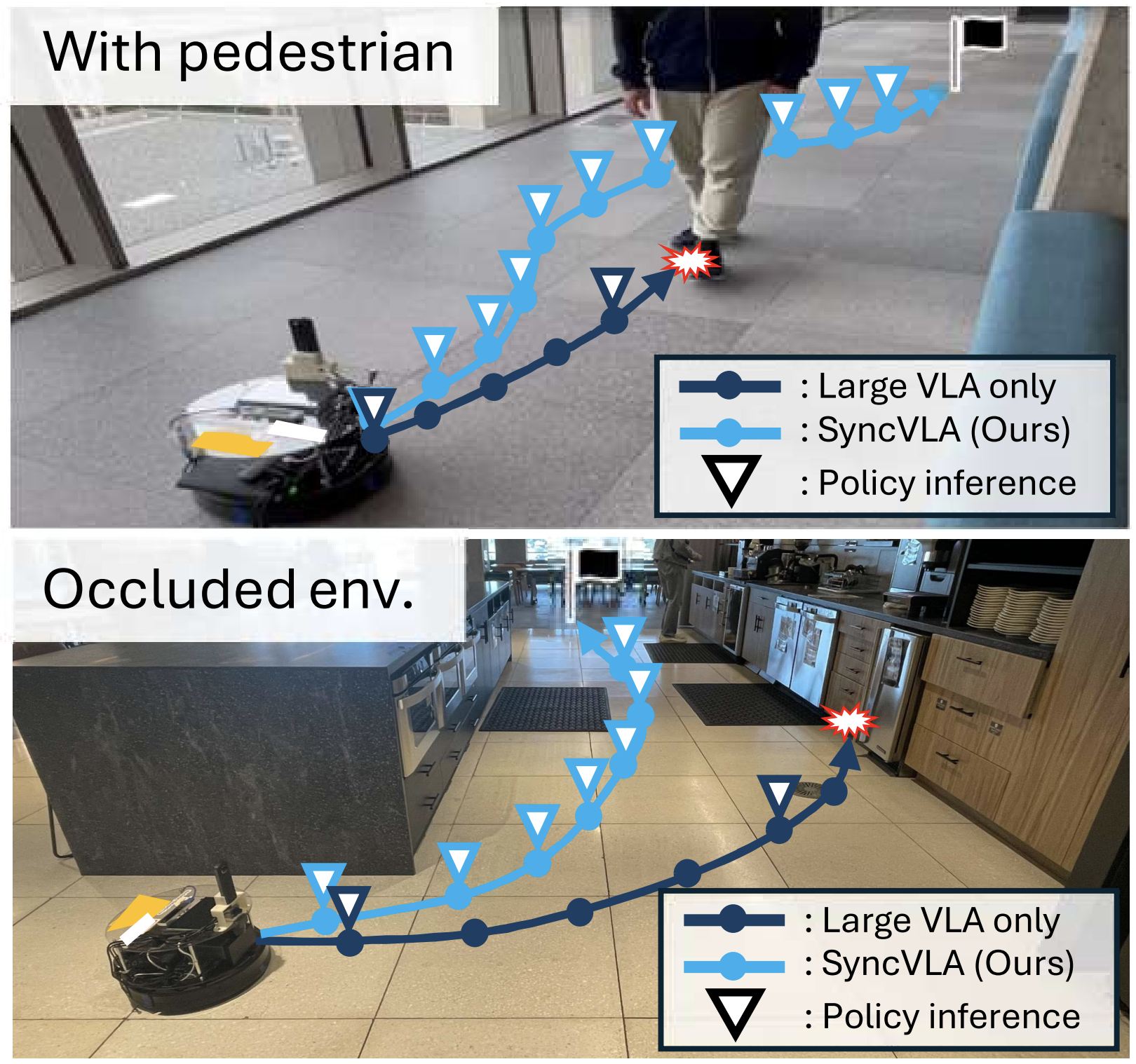
AsyncVLA: An Asynchronous VLA for Fast and Robust Navigation on the Edge
ArXiV pre-print
TLDR:We introduce AsyncVLA, an asynchronous control framework that enables real-time deployment of large robotic foundation models while handling network and inference latency.@misc{hirose2026asyncvlaasynchronousvlafast, title={AsyncVLA: An Asynchronous VLA for Fast and Robust Navigation on the Edge}, author={Noriaki Hirose and Catherine Glossop and Dhruv Shah and Sergey Levine}, year={2026}, eprint={2602.13476}, archivePrefix={arXiv}, primaryClass={cs.RO}, url={https://arxiv.org/abs/2602.13476}, } -

Steerable Vision-Language-Action Policies for Embodied Reasoning and Hierarchical Control
ArXiV pre-print
TLDR:We introduce Steerable Policies: VLAs trained on rich synthetic commands at various levels of abstraction, like subtasks, motions, and grounded pixel coordinates. By improving low-level controllability, Steerable Policies can unlock pretrained knowledge in VLMs, enabling improved task generalization.@misc{chen2026steerablevisionlanguageactionpoliciesembodied, title={Steerable Vision-Language-Action Policies for Embodied Reasoning and Hierarchical Control}, author={William Chen and Jagdeep Bhatia and Catherine Glossop and Nikhil Mathihalli and Ria Doshi and Andy Tang and Danny Driess and Karl Pertsch and Sergey Levine}, year={2026}, eprint={2602.13193}, archivePrefix={arXiv}, primaryClass={cs.RO}, url={https://arxiv.org/abs/2602.13193}, } -
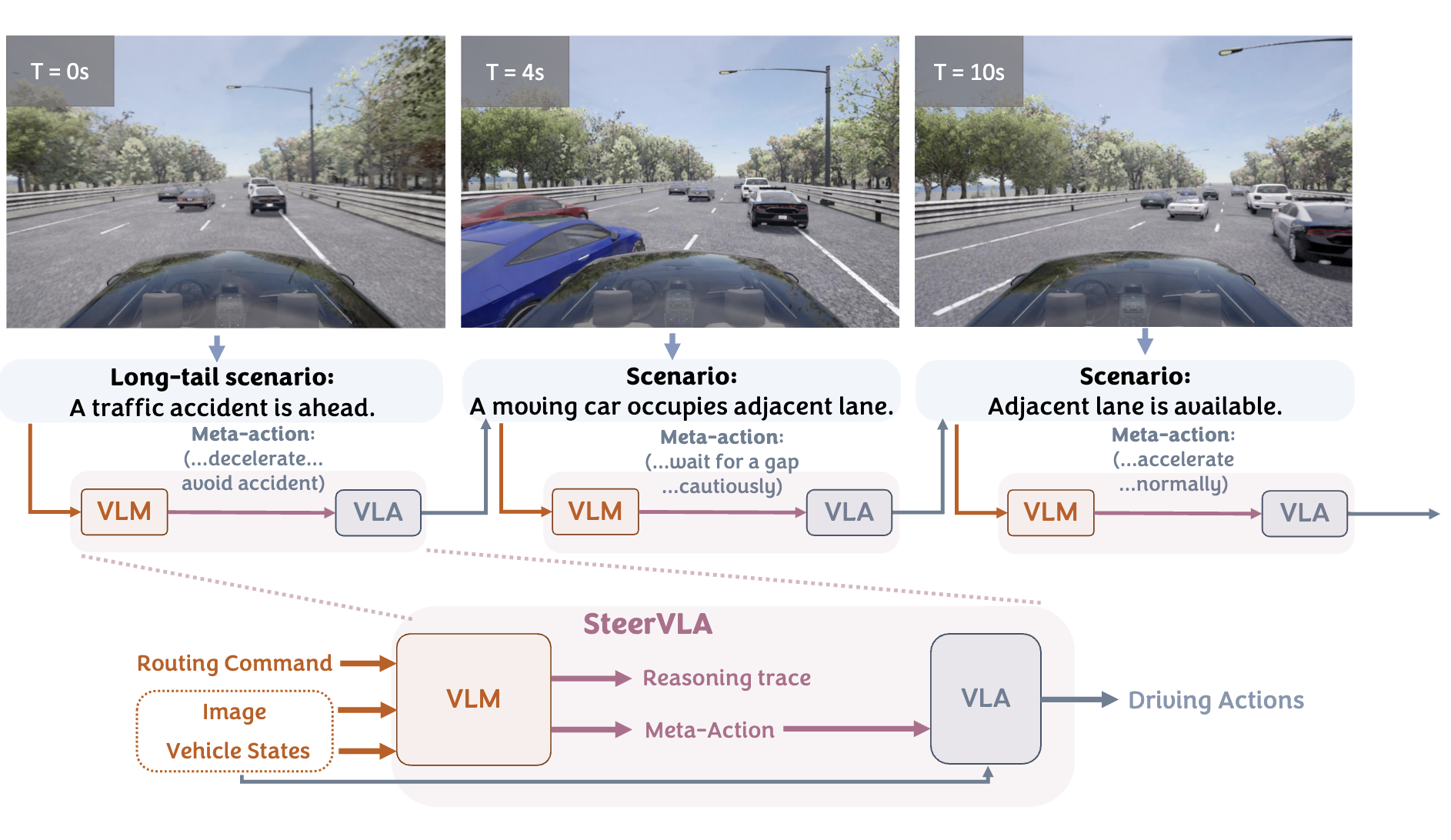
SteerVLA: Steering Vision-Language-Action Models in Long-Tail Driving Scenarios
ArXiV pre-print
TLDR:We propose SteerVLA, which leverages the reasoning capabilities of VLMs to produce fine-grained language instructions that steer a vision-language-action (VLA) driving policy. Key to our method is this rich language interface between the high-level VLM and low-level VLA, which allows the high-level policy to more effectively ground its reasoning in the control outputs of the low-level policy. To provide fine-grained language supervision aligned with vehicle control, we leverage a VLM to augment existing driving data with detailed language annotations, which we find to be essential for effective reasoning and steerability. We evaluate SteerVLA on a challenging closed-loop benchmark, where it outperforms state-of-the-art methods by 4.77 points in overall driving score and by 8.04 points on a longtail subset.@misc{gao2026steervlasteeringvisionlanguageactionmodels, title={SteerVLA: Steering Vision-Language-Action Models in Long-Tail Driving Scenarios}, author={Tian Gao and Celine Tan and Catherine Glossop and Timothy Gao and Jiankai Sun and Kyle Stachowicz and Shirley Wu and Oier Mees and Dorsa Sadigh and Sergey Levine and Chelsea Finn}, year={2026}, eprint={2602.08440}, archivePrefix={arXiv}, primaryClass={cs.RO}, url={https://arxiv.org/abs/2602.08440}, } -

π∗0.6: a VLA That Learns From Experience
ArXiV pre-print
TLDR:We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. RECAP starts by pre-training a generalist VLA with offline RL, which we call π∗0.6, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the π∗0.6 model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine.@misc{intelligence2025pi06vlalearnsexperience, title={$\pi^{*}_{0.6}$: a VLA That Learns From Experience}, author={Physical Intelligence and Ali Amin and Raichelle Aniceto and Ashwin Balakrishna and Kevin Black and Ken Conley and Grace Connors and James Darpinian and Karan Dhabalia and Jared DiCarlo and Danny Driess and Michael Equi and Adnan Esmail and Yunhao Fang and Chelsea Finn and Catherine Glossop and Thomas Godden and Ivan Goryachev and Lachy Groom and Hunter Hancock and Karol Hausman and Gashon Hussein and Brian Ichter and Szymon Jakubczak and Rowan Jen and Tim Jones and Ben Katz and Liyiming Ke and Chandra Kuchi and Marinda Lamb and Devin LeBlanc and Sergey Levine and Adrian Li-Bell and Yao Lu and Vishnu Mano and Mohith Mothukuri and Suraj Nair and Karl Pertsch and Allen Z. Ren and Charvi Sharma and Lucy Xiaoyang Shi and Laura Smith and Jost Tobias Springenberg and Kyle Stachowicz and Will Stoeckle and Alex Swerdlow and James Tanner and Marcel Torne and Quan Vuong and Anna Walling and Haohuan Wang and Blake Williams and Sukwon Yoo and Lili Yu and Ury Zhilinsky and Zhiyuan Zhou}, year={2025}, eprint={2511.14759}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2511.14759}, } -
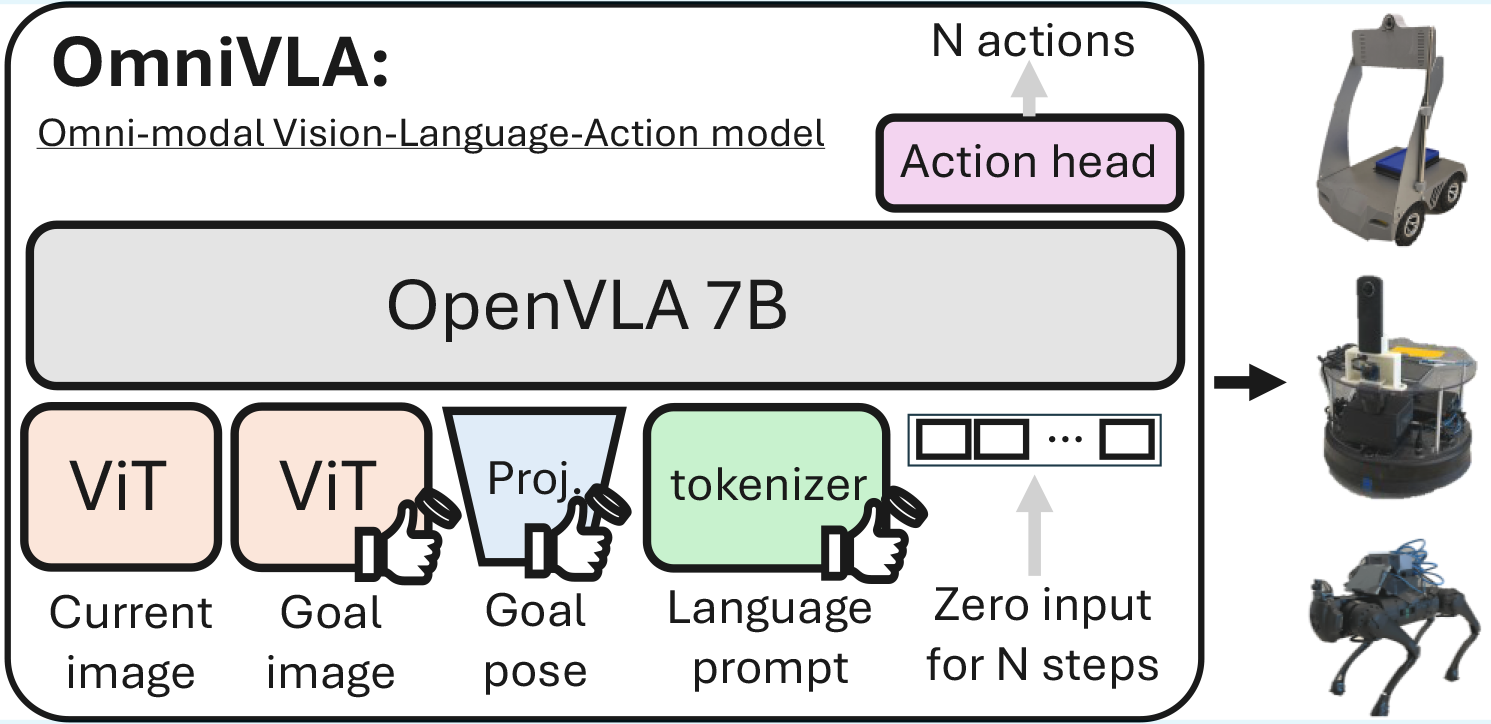
OmniVLA: An Omni-Modal Vision-Language-Action Model for Robot Navigation
ICRA 2026
TLDR:We introduce OmniVLA, a VLA trained with three primary goal modalities: 2D poses, egocentric images, and natural language, as well as their combinations. This encourages the policy to develop richer geometric, semantic, and visual representations. OmniVLA, achieves strong generalization to unseen environments, robustness to scarce modalities, and the ability to follow novel natural language instructions.@misc{hirose2025omnivlaomnimodalvisionlanguageactionmodel, title={OmniVLA: An Omni-Modal Vision-Language-Action Model for Robot Navigation}, author={Noriaki Hirose and Catherine Glossop and Dhruv Shah and Sergey Levine}, year={2025}, eprint={2509.19480}, archivePrefix={arXiv}, primaryClass={cs.RO}, url={https://arxiv.org/abs/2509.19480}, } -
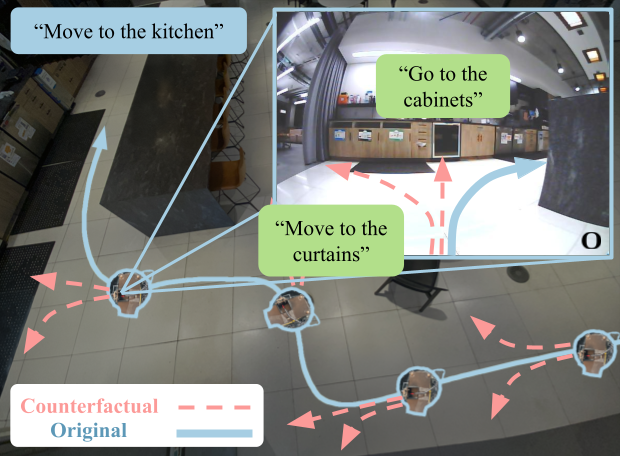
CAST: Counterfactual Labels Improve Instruction Following in Vision-Language-Action Models
ArXiV pre-print
TLDR:We introduce CAST, a method for augmenting robotics datasets with counterfactual trajectories to improve language following in vision-language-action models@misc{glossop2025castcounterfactuallabelsimprove, title={CAST: Counterfactual Labels Improve Instruction Following in Vision-Language-Action Models}, author={Catherine Glossop and William Chen and Arjun Bhorkar and Dhruv Shah and Sergey Levine}, year={2025}, eprint={2508.13446}, archivePrefix={arXiv}, primaryClass={cs.RO}, url={https://arxiv.org/abs/2508.13446}, } -

-
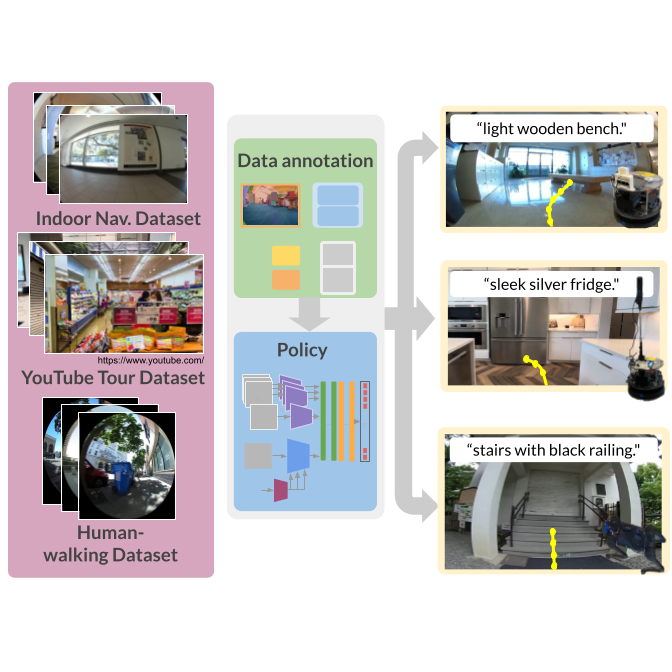
LeLaN: Learning A Language-Conditioned Navigation Policy from In-the-Wild Videos
CoRL 2024
TLDR: We annotated 100s of hours of in-the-wild video using a self-supervised pipeline to train a robust language-conditioned last-mile navigation policy@inproceedings{hirose24lelan, title={LeLaN: Learning A Language-Conditioned Navigation Policy from In-the-Wild Video}, author={Noriaki Hirose and Catherine Glossop and Ajay Sridhar and Dhruv Shah and Oier Mees and Sergey Levine}, booktitle={Conference on Robot Learning}, year={2024} } -
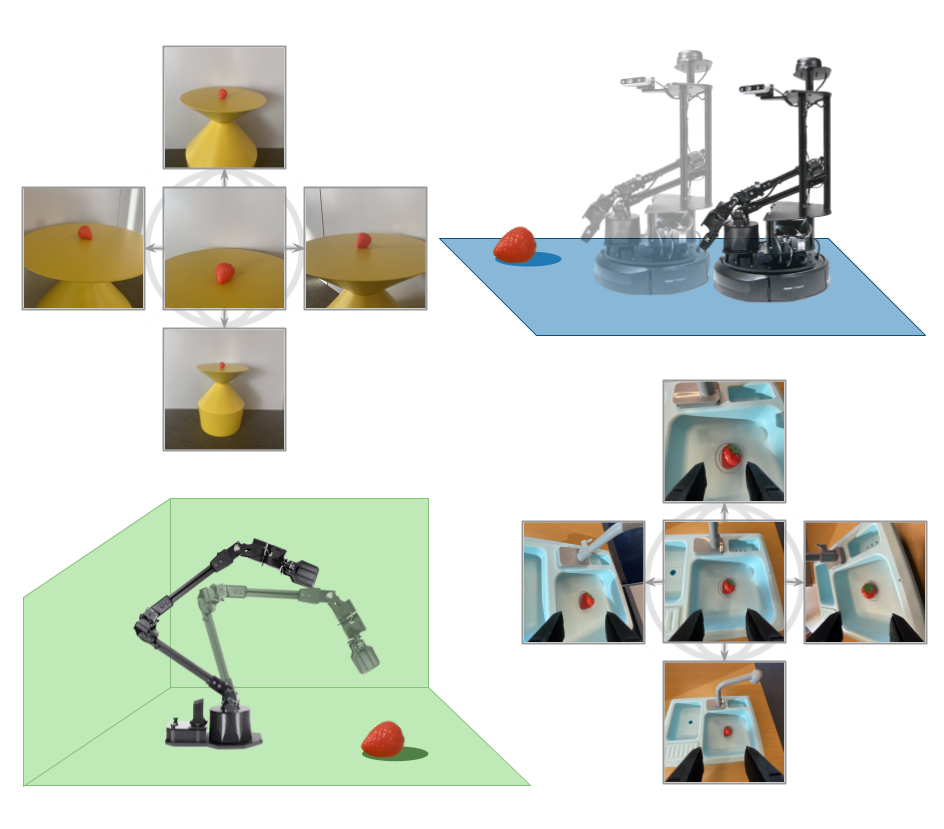
Pushing the Limits of Cross-Embodiment Learning for Manipulation and Navigation
RSS 2024
TLDR: We train a single policy that can perform both navigation and manipulation tasks on data from vastly different embodiments (including wheeled robots, quadrupeds, various manipulators, and self-driving vehicles).@article{yang2024pushing, title={Pushing the Limits of Cross-Embodiment Learning for Manipulation and Navigation}, author={Yang, Jonathan and Glossop, Catherine and Bhorkar, Arjun and Shah, Dhruv and Vuong, Quan and Finn, Chelsea and Sadigh, Dorsa and Levine, Sergey}, journal={arXiv e-prints}, pages={arXiv--2402}, year={2024} } -

NoMaD: Goal Masking Diffusion Policies for Navigation and Exploration
ICRA 2024 (Best Paper Award)
TLDR: We train a single diffusion policy on robot navigation data across different embodiments and environments that can perform both goal-oriented and goal-agnostic navigation.@article{sridhar2023nomad, author = {Ajay Sridhar and Dhruv Shah and Catherine Glossop and Sergey Levine}, title = {{NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration}}, journal = {arXiv pre-print}, year = {2023}, url = {https://arxiv.org/abs/2310.07896} } -
Characterising the Robustness of Reinforcement Learning for Continuous Control using Disturbance Injection
NeurIPS 2022 TEA and DistShift Workshops
TLDR: We empirically evaluate the robustness of different reinforcement learning algorithms to action, observation, and environmental disturbances.@misc{glossop2022characterisingrobustnessreinforcementlearning, title={Characterising the Robustness of Reinforcement Learning for Continuous Control using Disturbance Injection}, author={Catherine R. Glossop and Jacopo Panerati and Amrit Krishnan and Zhaocong Yuan and Angela P. Schoellig}, year={2022}, eprint={2210.15199}, archivePrefix={arXiv}, primaryClass={cs.RO}, url={https://arxiv.org/abs/2210.15199}, }